Abstract
This first article in the Easy IWA series details the regular requirement for a referentially complete database schema along with the capability to generate and load data during testing and POC exercises. This article provides information on implementing the TPCH database schema in IBM Informix, the dbgen data generation utility and loading the generated data.
Content
The TPCH database and dbgen data generation utility, courtesy of http://www.tpc.org, were developed to provide an approach to benchmarking and include:
- The tpch Database structure
- A referentially complete database schema
- The tpch dbgen utility
- A utility to populate the database with a specified amount of data (Scale Factor – SF)
- The tpch benchmark queries – not detailed here
- A set of pre-defined data warehouse queries to run against the database
This article details the creation of the tpch database and population using the dbgen utility to generate data; data population is detailed using flat files generated by dbgen and also pipes.
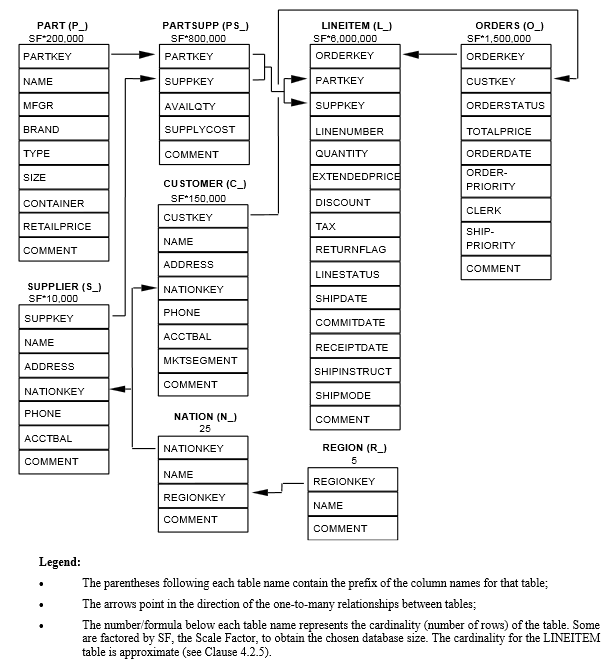
In essence, the schema consists of 8 tables, 8 explicit unique indexes supporting 8 primary keys and 9 explicit indexes supporting 9 foreign keys.
Download the following zip file http://www.tpc.org/tpch/spec/tpch_2_17_0.zip to a temporary directory and unzip.
Go to the extracted tpch_2_17_0/dbgen directory and copy makefile.suite to Makefile; within the Makefile amend the following to suit your environment:
Then run make ensuring a clean compilation!
After making sure that there is adequate filesystem disk space available (i.e. more than 1 GB!), run ./dbgen –s 1
If the following files are produced, then dbgen has been successfully built:
For completeness and readability, perform the following:
- Remove the just generated .tbl files under ../tpch_2_17_0/dbgen
- Create a new directory, /home/Informix/dbgen_article (for example)
- Copy ./tpch_2_17_0/dbgen/dists.dss to /home/Informix/dbgen_article/
- Copy ./tpch_2_17_0/dbgen/dbgen to /home/Informix/dbgen_article/
- ./dbgen —
- Show complete usage
- ./dbgen –s 1 –f
- Force overwrite of existing files
- ./dbgen –s 1 –T c
- Generate just the customers (there are options for each table)
The generated data can also be placed, in parallel, on pipes with a slight amendment to the above script:
However, the data generation will not proceed until each pipe has started to be read; the following helper script can be used for flushing all data through the pipes:
Hint – wait until 100% displayed for each dbgen execution before executing this script.
With the above information, there are two approaches that can be followed to load data; one is loading the data from flat files and the second is loading the data from pipes.
- Creation of the database
- Creation of the region table as raw
- Creation of an external “disk” table region_ext “sameas” region
- Insertion of data into the region table
- Altering the region table to standard
- The addition of a unique index and the primary key to the region table
Hint – the DBDATE format is YMD4-Copy to Clipboard
Hint – the database, jj_dbgen, cannot be dropped until a Level 0 archive is performed
A fake backup can be run using onbar –b –F
Alternatively, the individual tables can be dropped without a Level 0 archive
- Remove the flat file “region.tbl” rm region.tbl
- Create the “region.tbl” as a pipe mknod region.tbl p
- Amend the external table definition for region_ext as a “pipe” create external table “informix”.region_ext sameas region using ( datafiles(“pipe:/home/informix/dbgen_article/region.tbl”));
- Prime the region pipe with data – note this will remain running ./dbgen –v –T r –s 1
Modify the database creation statement to denote an appropriate dbspace.
In order to load the data from pipes, change the external table definitions from “disk” to “pipe” and modify the jj_dbgen_data.sh script to generate the data on pipes and run in the background ./jj_dbgen_data.sh &, then run dbaccess – jj_dbgen.sql.
It should be noted that the 12.10.xC4 feature of “NOVALIDATE” when creating foreign keys is being used; remove the “NOVALIDATE” if working with versions prior to 12.10.FC4
Conclusion
For testing and POC exercises, often what is required is a populated database of a specific size; this article provides enough information to implement the TPCH database with a data population of any size ranging from 1 GB to any size and demonstrates using IBM Informix external tables from “disk” or “pipe”.
Disclaimer
The code fix suggested above is provided “as is” without warranty of any kind, either express or implied, including without limitation any implied warranties of condition, uninterrupted use, merchantability, fitness for a particular purpose, or non-infringement.

