Abstract
What is TimeSeries? TimeSeries has actually been around for a fairly long time dating back to 1992 where it started at Illustra. It was then ported to Informix when Illustra was acquired by IBM, followed by the first Informix release of the TimeSeries Data Blade in 1996. However, it is now beginning to generate a lot of hype and interest. The reason why we are only now starting to hear about TimeSeries with any persistence is quite simply due to need and achievability. By this I mean: firstly, there are now larger amounts of data stored about numerous things than there were 15 years ago – simply put data is increasingly the lifeblood of every industry. Secondly, the hardware capabilities have progressed sufficiently to manage these increasing amounts of data; however, due to these huge data stores, things are becoming sluggish, and companies are looking for improved ways to store and manage their data: enter TimeSeries…again!
Content
A good introduction to TimeSeries is to examine the architecture of how the data is stored in a broad sense. Rajesh Nair has written a nice introduction to TimeSeries which can be found here: Power of Informix Extensions. Below is a snippet of Nair’s key points regarding the architecture.
Assume the scenario of a race tracking the position of a player:
| player_id | posistion_info |
|---|---|
| P1 | TimeSeries(pos_chg) |
| P2 | TimeSeries(pos_chg) |
![]()
| t1 | t2 | t3 | t4 | ... |
![]()
| TimeStamp | position | place_id |
|---|---|---|
| DATETIME YEAR TO FRACTION (5) | Point | CHAR |
As you can see, instead of a row per timestamp, all entries related to the time series are entered into the same row of an Informix table. A TimeSeries data type allows you to keep a single row for every player regardless of how many times assets change hands or how many times they change their position. This also helps save storage space.
To understand how this works, think of the TimeSeries column as a container for a row subtype. This subtype represents a structure of elements (t1, t2, t3 …). Each element represents a single set of data for a timestamp. In the positioning table example, this sub-type is labelled “pos_chg”. The TimeSeries data type acts as a constructor for this subtype as shown in the table: TimeSeries (pos_chg).
Again, each element (t1, t2, t3 …) is another row data type that begins with the timestamp column and has additional columns. The Timestamp column can be used as an index for the elements. Below is another illustration which may be easier to understand:
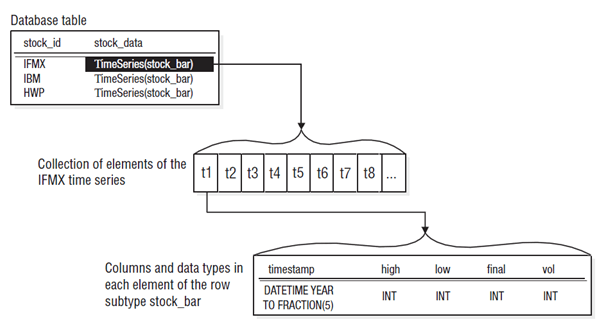
TimeSeries data type architecture – IBM Informix TimeSeries Data User’s Guide
To show the comparison between TimeSeries and RDBMS implementations of data see the diagram below:
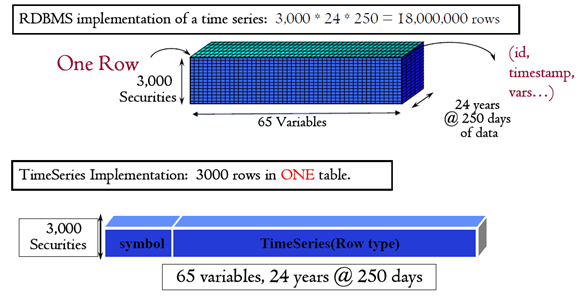
Murthy, K –Using IDS Extensibility in Applications 2005.
One of the major stems of interest around TimeSeries is in the growth of Smart Meter Data Management. A report from the BBC in 2008 found in here: Means to Identify Energy Use highlights this interest. To illustrate a bit more about Smart Meters and how TimeSeries ties in take a look at Simon David’s (Cosmo) presentation about – why TimeSeries is the only option.
Conclusion
OK, so now you should have a high level understanding of TimeSeries; however, you’re probably thinking how can this benefit me? Well, TimeSeries has many potential applications – being time based data it is obviously going to be suited to an application that records data at timed intervals, consider the buzz word “tick-data”; here, this magic word connects the dots for what TimeSeries could be used for, so any data source that has a pulse may benefit from the power of TimeSeries – for example: Capital markets, telecommunications, manufacturing, logistics, scientific research etc… worth thinking about?
Disclaimer
The code fix suggested above is provided “as is” without warranty of any kind, either express or implied, including without limitation any implied warranties of condition, uninterrupted use, merchantability, fitness for a particular purpose, or non-infringement.
Extras
- There are two kinds of time series:
Regular
A regular time series stores data for regularly spaced time-points. Regular time series are appropriate for applications that record entries at predictable time-points, such as stock summary data that is recorded every business day.Irregular
An irregular time series stores data for a sequence of arbitrary time-points. Irregular time series are appropriate when the data arrives unpredictably, such as when the application records every stock trade as it happens.- Every time series is associated with a calendar.
- Calendars
- Calendar Patterns
- Time Series Origin
- Offset
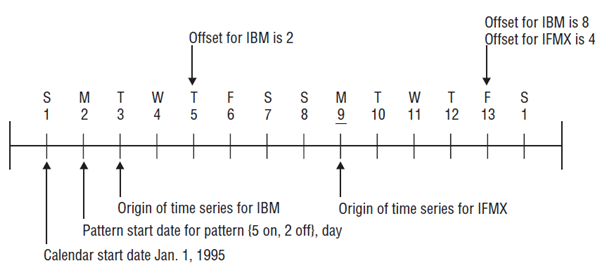 Sample time series time line- IBM Informix TimeSeries Data User’s Guide
This illustration covers the first two weeks of 1995. It shows:
Sample time series time line- IBM Informix TimeSeries Data User’s Guide
This illustration covers the first two weeks of 1995. It shows:
- Two regular time series (IBM and IFMX), their origins, and their offsets
- A calendar with its start date, calendar pattern, and calendar pattern start date
- Calendars are represented by the Calendar data type, which is composed of the following values:
Start date
- The date the calendar begins.
Pattern
- A regularly occurring set of valid and invalid time intervals.
Interval
- The calibration of the calendar pattern.
Pattern start date
- The date the calendar pattern starts. This date must be later than or equal to the calendar start date. This date must be less than one calendar pattern length after the calendar start date.
- Each calendar has a calendar pattern of time intervals that are either valid or invalid, with the beginning of the calendar pattern specified by the calendar pattern start date.
Contact us
If you have any questions or would like to find out more about TimeSeries and Informix, simply contact us.
- There are two kinds of time series:
Regular
A regular time series stores data for regularly spaced time-points. Regular time series are appropriate for applications that record entries at predictable time-points, such as stock summary data that is recorded every business day.Irregular
An irregular time series stores data for a sequence of arbitrary time-points. Irregular time series are appropriate when the data arrives unpredictably, such as when the application records every stock trade as it happens.- Every time series is associated with a calendar.
- Calendars
- Calendar Patterns
- Time Series Origin
- Offset
Sample time series time line- IBM Informix TimeSeries Data User’s Guide
This illustration covers the first two weeks of 1995. It shows:
- Two regular time series (IBM and IFMX), their origins, and their offsets
- A calendar with its start date, calendar pattern, and calendar pattern start date
- Calendars are represented by the Calendar data type, which is composed of the following values:
Start date
- The date the calendar begins.
Pattern
- A regularly occurring set of valid and invalid time intervals.
Interval
- The calibration of the calendar pattern.
Pattern start date
- The date the calendar pattern starts. This date must be later than or equal to the calendar start date. This date must be less than one calendar pattern length after the calendar start date.
- Each calendar has a calendar pattern of time intervals that are either valid or invalid, with the beginning of the calendar pattern specified by the calendar pattern start date.

